DuckDNS on the Ubiquiti EdgeRouter
My current networking home setup consists of the Ubiquiti Networks ERPOE-5 Edgemax as a router and the ZyXEL Dual Radio 11AC Ceiling AP (NWA1123-AC).
So far, I’m reasonably happy with both and I like the idea of being able to just switch access points as new standards come along while leaving the routing/switching part the same. Being able to use PoE also helps reduce the amount of power supplies I have to cram into my little homeserver and networking cabinet.
Comcast provides me with a Dynamic WAN IP Address, but I’d love to be able to e.g. VPN back into my home network without having to know the current IP.
This is where a dynamic DNS service comes in. After a bit of looking around, I picked Duck DNS. They seem to be one of those nice little “it’s free and works for now” sevices run by people as a hobby as opposed to all of the other free services that force you to log into the webinterface every week or to buy their premium plan.
To get your Duck DNS data:
- log into their website and go to their install page.
- Chose the domain you set up from the dropdown and click on the
- Click the “DynDns” button in the “Standards” area of the website.
This should give you the generated token for your account. Now hop on over to the DynDNS Webinterface of your EdgeOS Router. As of 1.7.0, these are the parameters you will have to enter to make it work:
Service: [custom -] duckdns
Hostname: thing in front of .duckdns.org (example.duckdns.org ==> example)
Login: nouser
Password: your generated password
Protocol: dyndns2
Server: www.duckdns.org
If you want to debug a bit on the commandline, you can run the following commands:
Show the current status:
$ show dns dynamic status
interface : eth0
ip address : 12.34.56.78
host-name : example
last update : Mon Sep 7 17:09:29 2015
update-status: good
Trigger an update
$ update dns dynamic interface eth0
Duckdns seems to be a decent free service. Especially for my use of dynamic DNS names which are really not all that important, I opted against moving a domain back over to namecheap and setting dyndns up on a personal domain or trying to use the cloudflare API for now.
Maybe on a rainy day :)
SRE Interviews in Silicon Valley
A few months ago I had several interviews at some of the bigger Silicon Valley tech companies. I learned a tremendous amount in the process and while I couldn’t openly talk about it back then, I thought that I should at least write down my experiencees after the fact.
Disclaimer
Some of these companies require NDAs for the interview process in case you run
into any secrets while you’re on site, so I won’t name any names or describe
any specific details.
This post is supposed to summarize the similarities between the companies and
to give an overview of what to expect during the tech interviewing process.
The position
My experiences were particular to the type of position I got approached for. The position was very similar for all of them. Some companies call it “Production Engineer”, some call it “Site reliability engineer” (SRE). The idea is the same. It is the middle ground between a systems engineer and a software engineer. The positions requires in depth knowledge of 5 different areas:
- Coding
- Systems
- Networks
- Troubleshooting
- Scalable Architectures
You don’t have to know all of them, but should at least have a good knowledge of 2-3 and a basic understanding of all of them.
Coding
For the SRE position, these are not usually the brain teasers you can read about in the tabloids. It also didn’t consist of very data structure heavy acrobatics (I didn’t have to rebalance red-black tree or implement mergesort)
Most of the time people just want to see that you can develop reasonably
complex tooling and know the pitfalls that you encounter in production.
It usually starts out as a basic task (e.g. log parsing, file pruning, …) and then gets extended a bit (“What if this had to run continuously?”).
The gotchas are the usual things that you run into when working on an actual
system and not just sitting in a lecture about one.
It starts with escaping spaces and ends at multiline syslog messages and
“does this file fit into RAM?” kind of problems. Most of the time, you get to
pick your programming language of choice. I would usually suggest Ruby or
Python. Nobody wants to get stuck in weird IO interfaces or languages that don’t support strings natively ;)
Depending on the interviewer, you might end up having to do a little bit of string manipulation (find all palindromes, group by x, …), but since most of these string manipulations are relatively approachable, I rather enjoyed myself even though I would classify my remaining theoretical datastructure/algorithm knowledge as “could need some polish”.
Systems
The systems part of the interviews is usually targeted towards Linux.
It includes Filesystem knowledge (What are Inodes?), knowledge about the process lifecycle (What is fork+exec? How do signal handlers work? Thread vs Process?), Linux internals (What is load? Describe the boot process? How does dynamic linking work?).
These all require relatively in depth answers of more than a sentence.
The more in detail you can go the better.
Networking
At least for me, this wasn’t too much about Spanning Tree or BGP.
The networking interviews targeted more on the application side of things.
A lot of conversations about TCP (Nagle’s algorithm, TCP CORK, …), DNS (Glue Records, recursive resolvers, …), IP (CIDR), SSL, …
I was once even asked what my favorite protocol was. Luckily I had skimmed my thesis on anonymous filesharing on the flight over, so I had some talking points :)
A lot of the time, you will hear open ended questions (“You type a URL in your browser and hit enter, what happens?”) and can go down the stack to your heart’s desire :)
Troubleshooting / Incident response
This part of the interview is the one that differs most between the companies.
It is probably also the hardest one to come up with as an interviewer.
It ranges from actual debugging of LAMP problems inside a VM to looking at alerts and prioritizing them, to looking at a 32 thread stacktrace and telling a
story of what happened.
Some of the interviewers are able to play a D&D style “dungeon master” role and
give you a hypothetical system on which a defect is manifesting itself. You then
have to describe your steps to zone in on the problem while the interviewer will
tell you the results of your queries (“I check for inodes using df -i” - “You see that you have a utilization of 30%”).
Scalable architectures
This is one of the interviews that is probably a big unknown to people who
have mostly dealt with smaller systems before.
The interview is usually an interactive whiteboarding session in which you have
to design a system that withstands a certain amount of requests.
The initial requirements are relatively tame and the interviewer will gradually
force your architecture to scale more and more. This is where you can bring in
your knowledge about load balancers, caching layers, consistent hashing and
sharding. Bonus points for fancy things like bloom filters of hyperloglog :)
It probably also doesn’t hurt to know some of the technology that has emerged from the company in question. Most of the tech companies have 1-2 open source projects that might be worth a look beforehand.
The interview process
It seems like all of the big tech companies have agreed on a way to do interviews.
Initially, I got contacted by a recruiter. This seems to usually happen either via LinkedIn or eMail (maybe via a github profile?).
Most recruiters will usually talk a bit about the position, learn about your
experience and once they deem you a fit, will do a little pop quiz.
The pop quiz will consist of a set of 20'ish questions about all of the topics
mentioned above. Usually they can be answered with a single word or two.
(“What port does DNS run on?”, “What is saved on an inode?”, …)
Once thethe initial screening is over and was successful, there will be 3-4 phone interviews of about 45-60 minutes each. The interviews will go into one of the topics mentioned above. The coding will be done using a collaborative online editor. This editor can also be used to paste stacktraces and log entries for systems questions. You might want to brush up on what all of the letters in vmstat mean ;)
At the end of each interview, there are usually 10 minutes set aside for
questions.
This is a good time to ask about the day to day stuff that the engineers might
be able to answer a bit better than the recruiter.
Once all of these phone interviews are over and went reasonably well, the fun part starts: the on-site!
For me, this meant free flights from Boston to San Francisco! Not only did this
allow me to escape the winter, but it also allowed me to spend some time driving around SF and the valley.
I had never been before and was able to connect with some old friends and
colleagues.
Usually the companies cover the whole trip. From airport parking to a rental car, an allowance for food and hotel stays, it’s all taken care of.
Preparation
Work is keeping me reasonably busy and I usually stay up to date by reading lots of blog-posts in my free time, so my only preparation for the interviews was the book Modern Operating Systems by Andrew Tanenbaum.
Besides a few google searches about interview questions and a look at Glassdoor, I think using the 5+ hour flight to read over the Tannenbaum book was probably the thing that helped me the most.
For the 3rd interview, I also spent some time reading Programming Pearls. Solving these kind of math heavy problems is nothing that comes naturally to me, but I think I got a bit of a better grasp about the problem space and how a different perspective can sometimes show up elegant solutions.
Conclusion
Honestly, the whole experience was highly entertaining and I learned a lot.
I didn’t actively look for a job, so I was able to come into those interviews
without any pressure on me.
It was nice to see how a well executed HR/Recruiting organization can work and
taking a peek inside all of these companies was really interesting.
I really enjoyed talking to the Engineers during the interviews and getting a
bit of a feeling for how the companies operate and what the people that make these giant infrastructures work do on a regular day.
As an added benefit, knowing one’s market value does help a lot on the professional development side of things.
US Global Entry for German Citizens
I recently read about German citizens being eligable for the US Global entry system. Seeing as I would love to avoid the 45 minute wait at the border after the 10 hour flight, I asked the German authorities for details. This is their answer:
Hiermit bestätigen wir Ihnen den Eingang Ihrer Anfrage und können Ihnen ergänzend folgende Informationen hierzu geben:
Das Bundesministerium des Innern und die U.S.-Behörden haben eine Verknüpfung der jeweiligen nationalen Trusted Traveler Programme vereinbart. Auf U.S.-Seite handelt es sich um das System Global Entry und auf deutscher Seite um die Automatisierte Biometriegestützte Grenzkontrolle (ABG). Diese Kooperationsvereinbarung ermöglicht es, am Global Entry registrierten U.S.-Staatsangehörigen an der ABG und umgekehrt an der ABG registrierten deutschen Staatsangehörigen am Global Entry teilzunehmen (Vielfliegerprogramm). Die Aufnahme in das Global Entry System über die Onlineregisrierung GOES erfordert daher die vorherige Teilnahme / Registrierung an der ABG.
Reisende werden bei uns im Servicecenter der Bundespolizei somit zunächst im deutschen ABG-Programm (Retinascan) registriert. Dazu benötigen wir einen gültigen, maschinenlesbaren Reisepass (mit Chip). Die Registrierung ist derzeit ausschließlich am Frankfurter Flughafen möglich und dauert etwa 20 Minuten. Nach der Registrierung erhalten Sie die Zugangscodes für die Anmeldung auf www.globalentry.gov.
Das Servicecenter befindet sich im Terminal 1 Abflug A neben Eingang 1. Unsere Öffnungszeiten sind grundsätzlich Mo - So 07:00 - 21:00 Uhr; als Kernzeit Mo - So 08:30 - 17:30 Uhr. Wenn Sie einen Termin benötigen, setzen Sie sich telefonisch oder per eMail mit uns in Verbindung.
Die beigefügten Unterlagen dienen zur Information. Sie können ausgefüllt mitgeführt werden, ist aber nicht zwingend notwendig. Bitte sehen Sie davon ab uns die übersandten Unterlagen vorab per E-Mail zuzusenden.
Wenn Sie von uns die Zugangscodes erhalten haben, müssen Sie sich für alles weitere online unter www.globalentry.gov anmelden. Die Anmeldung ist kostenpflichtig und kostet 100,00 $. Nach etwa drei Wochen erhalten Sie einen Termin als Vorschlag zur persönlichen Vorstellung in den Vereinigten Staaten. Erst danach werden für Sie die Global-Entry-Kioske freigeschaltet sein.
Darüber hinaus können Sie sich auf den folgenden Internetseiten über EasyPASS, ABG+ und Global Entry informieren:
http://www.bundespolizei.de/DE/01Buergerservice/Automatisierte-Grenzkontrolle/ABG/abg_node.html
http://www.auswaertiges-amt.de/DE/Laenderinformationen/00-SiHi/UsaVereinigteStaatenSicherheit.html
www.globalentry.gov
Wir hoffen Ihnen mit diesen Informationen weitergeholfen zu haben und stehen Ihnen auch weiterhin bei Fragen gerne zur Verfügung.
Mit freundlichen Grüßen
Boston DevOps - Heartbleed at Acquia
These slides were part of my presentation at Boston DevOps.
The topic of the night was “Let’s discuss Agility vs Resilience - 5 9s in the post Heartbleed world”. The ideas for presentations given on the invite were:
- How has your organization responded to this?
- Which of your procedures or processes changed?
- Have previously uninterested stakeholders taken notice?
- Have any changes been made to your Continuous Integration systems?
So this one is about how we handled the OpenSSL Heartbleed Vulnerability at Acquia from a technical and a communication perspective.
The PDF version of the talk is available for download over here.
L1 US Visa Interview Experiences in Frankfurt
This one is a non-technical post. I decided to write this because all related information is spread around various forums and often outdated (consulate moved, other procedures). I personally like to be as prepared as possible, so having this online might benefit some people that were in a similar situation as I was and save them some searching. I won’t go into detail on the whole visa process since that’s something best left up to the lawyers (according to lawyers). This post describes things that I dealt with on my own after the initial application was already done.
Pre-appointment
While filling out a DS-2019 is necessary, it’s all pretty selfexplanatory. The first thing that I’d consider to be a bit out of the ordinary was paying the visa fee using the Roskos Meier Visasysytem. I don’t know how an insurance agency from Berlin got into the job of taking payments for all American consulates, especially considering that the 10$ interview application fee can be paid using a credit card, but I guess that’s a bit off-topic. One important thing to pay attention to is, that setting up an appointment on the internet will allow you to sign up for one about a week from the day you apply. This was at least the case for me in the ‘off season’ (read: H1B applicants are mostly processed by now). You WILL need to show the roskos meier printout when you’re arriving at the consulate. Be sure to check for any bank holidays and weekends between now and your chosen appointment. For me, the confirmation took 4 business days to arrive (+ 2 weekend days and 1 bank holiday). The email arrived at 08:23 in the morning, so it might be an automated system.
At the appointment
Parking
I decided to take the car because the VVS/SSB and Deutsche Bahn recently had all sorts
of problems bringing people to where they need to go on time.
As you can see on google street view,
there is plenty of free street parking available right next to the consulate.
I had an early-ish (9.15) appointment and was one of a handful of cars. The employees
seem to have their own parking spots, so I think the street spots won’t be all that
crowded thoughtout the day.
There is also a UBahn (U5) stop right down the street called “Gießener Straße”
which will take you directly to the Hauptbahnhof (15-20 minutes).
Date and time
Seeing as I went past 3 major cities on my way to Frankfurt, I decided to add a little time buffer for slow traffic along the way. There was pretty much no traffic at all, so I arrived around 8.30. When asking the security guard upfront, he said that I can probably just stand in line, as long as I have SOME form or appointment, they’ll let me in. So if there isn’t too much of a line, you might as well try.
The road to rome
To end up in the final room that does the processing you will:
- Wait in line in front of the entrance. They have those little heat radiators, so even in a bit of a colder weather it’s pretty pleasant. There are lines for citizens and non-citizens. At the end of the line, you’ll get assigned a number.
- Once you have the number, you move one queue to the right and put everything you have in your pockets (and your belt) in a clear plastic bag that you’ll be handed by the security guard.
- Once they let you into the building, you’ll get directed through an airport-style metal detector.
- After passing though the detector, you’ll have to walk through the courtyard into the next building (with your belongings still in the bag).
- In the beginning of the next building, there’s a little entrace hall with a place to put the plastic bag after you’ve emptied it.
- After that entrance hall, you’ll walk up to the large room where the bureaucratic magic happens. It’s a pretty generic system where you basically stand in a few more lines walking up to the people doing the processing.
In case of a longer waiting period, there are snack machines (German drinks, German candy) and a bathroom available. They put a “dyson airblade” in the bathroom, so I finally understood where all those visa fees ended up at ;)
The “interview questions”
After giving them your passport and fingerprints at the first booth and having
them reconfirmed at the second one, you will be at the final step of your journey.
I didn’t need to give them my print outs of the passport picture. They said that
if the DS-2019 looks fine, they will just take the digital one.
After waiting for my number (the one you got at the very first step) to show up,
I was at the last step of the process, the interview stage.
As far as the interview questions go, the were pretty generic in my case.
I assume just to make sure I actually know who I am and what I’m doing.
From what I recall, they were something along these lines:
- Is X the company you work for?
- What do you do there? (“I’m a software engineer” was detailed enough.)
- How long have you been working for X?
- What does your company do?
- For how long do you plan to stay?
- Which state are they in?
Seeing as both the lady behind the glass and the company I work for were from Massachusetts, I had a bit of smalltalk about how cold winters are in Boston (always a favorite) and how little sun we get around Germany’s latitude. It was all very pleasant and everyone seemed to be in a good mood. After you (hopefully) get the magic “Your visa is approved”, you can exit the building the way you came in.
Post-appointment
Getting the visa in your passport means that they’ll take a full page of your little passport book and glue in a colorful piece of paper with your picture on it. It basically says how long the visa is valid for (5 years in my case) and adds additional notes (“must present approved I-797 or I-129S at POE”). You don’t have to be at home for DHL express, they will just put it in your mailbox.
That was pretty much it, hope I could help whoever was directed here by a google search :)
IP to Countrycode With Ruby
Long time no blog!
I’ve had this script sitting around for a while now and never really quite know where to post it.
It isn’t really worth turning into a Gem and while I just posted it on Github, posting it here will probably give people a few more google results.
Since it’s the internet, I’m sure there are some edge cases where this doesn’t work or where it returns incorrect data. It’s also very fragile when it comes to error handling with the downloads, so don’t use it to power your nuclear power plant ;)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | |
Backing Up FitBit Data Using Their API
I love the idea of the Quantified Self movement. I love collecting data, trying to see connections and monitoring my self improvement process. I’ve been collecting GPX traces while running for quite a while, so it isn’t all that unexpected that the fitbit was a gadget that was right up my alley. It allows you to record the amount of steps you take like every other pedometer, but thanks to a few more sensors, it also can tell you how many floors you’ve climbed, how many kilometers ou traveled and even how often you worke up while sleeping.
It syncs wirelessly, the battery lasts a long time and it is small enough that it isn’t an annoyance to carry arround all day.
The only downside is the webservice itself. It’s not that I dislike their site itself, quite to the contrary. The annoying part is that I’d have to subscribe to their premium plan to get a hold of my raw data. I’m not actually looking to use any of the other premium features, so just paying 50$/yr because they hold my data hostage was kind of a pain.
The nice part however is, that they provide an API that allows you to programmatically grab at least an overview of activity and sleep stats. It misses the actual timeframes (“you walked 1000 steps between 3 and 3,15”, “you woke up at 3, 3:45 and 5”) but it provides you with an ok summary (steps per day, fell asleep at time x, …).
I was a bit afraid that I’d have to screen scrape their site to get to my data, but not only didn’t I have to do that, I also didn’t have to deal with the oauth stuff myself either.
Zachery Moneypenny (“whazzmaster”) had already created a client library for their API and provided a bit of sample code.
Using that library I was able to whip up a quick incremental backup script that saves the activities and sleep data as something machine readable.
This is an example of what the activity data looks like:
$ cat 2012_09_10_activities.yaml
---
activities: []
goals:
activeScore: 1000
caloriesOut: 3092
distance: 8.05
floors: 10
steps: 10000
summary:
activeScore: 762
activityCalories: 1362
caloriesOut: 2885
distances:
- activity: total
distance: 6.43
- activity: tracker
distance: 6.43
- activity: loggedActivities
distance: 0
- activity: veryActive
distance: 2.25
- activity: moderatelyActive
distance: 3.36
- activity: lightlyActive
distance: 0.81
- activity: sedentaryActive
distance: 0
elevation: 9.14
fairlyActiveMinutes: 102
floors: 3
lightlyActiveMinutes: 139
marginalCalories: 913
sedentaryMinutes: 651
steps: 8114
veryActiveMinutes: 33
And the sleep data:
$ cat 2012_09_10_sleep.yaml
---
sleep:
- awakeningsCount: 8
duration: 30900000
efficiency: 97
isMainSleep: true
logId: 16236289
minutesAfterWakeup: 1
minutesAsleep: 471
minutesAwake: 16
minutesToFallAsleep: 27
startTime: '2012-09-10T00:56:00.000'
timeInBed: 515
summary:
totalMinutesAsleep: 471
totalSleepRecords: 1
totalTimeInBed: 515
You can find the script in my github repo. It’s not properly packaged and the Readme could use some polish, but this is more of a ‘scratching my own itch’ thingy that I thought might just save somebody 15 minutes.
Ruby, OpenSSL and ECONNRESET
UPDATE: After having seen this quite a few times over the last few months, a quick update: This is an incompatibility between how OpenSSL 0.98 and 1.x treat TLS errors: http://sourceforge.net/p/curl/bugs/1037/?page=1
Moneyquote:
This problem has to do with the TLS SNI extension.
If curl sends an SNI hostname that the server does not recognize, the server will send back a TLS Alert record with Level 1 (Warning) and Code 112 (Unrecognized name) to notify the client that the server may not do what the client is expecting (that's what reason(1112) is referring to).
In the case of Apache, if your VirtualHost does not contain a ServerName or ServerAlias statement which explicitly matches the specified domain name, Apache will send back this TLS Alert.
And this means:
So it looks like openssl 0.9.8 will fail if it receives any TLS Alert records while waiting for the Server Hello record. openssl 1.0.0 has been updated to ignore TLS Alerts that are Warnings:
http://cvs.openssl.org/chngview?cn=14772
Original post:
I ran into a strange ‘bug’ that was a little bit more annoying to debug.
Apparently OpenSSL 1.x that is getting installed by brew doesn’t seem to be 100% compatible with Ruby, at least when you install it using RVM.
I ran into a reproducible problem when trying to connect to a salesforce sandbox account. This could be distilled down to this snipped:
1 2 3 4 5 6 7 8 | |
Which resulted in this sad exception after 30 seconds or so:
Errno::ECONNRESET: Connection reset by peer - SSL_connect
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:799:in `connect'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:799:in `block in connect'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/timeout.rb:54:in `timeout'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/timeout.rb:99:in `timeout'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:799:in `connect'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:755:in `do_start'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:744:in `start'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:1284:in `request'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:1307:in `send_entity'
from /Users/mseeger/.rvm/rubies/ruby-1.9.3-p125/lib/ruby/1.9.1/net/http.rb:1096:in `post'
It turns out that RVM can also install openssl, and it decides to go for version 0.9.8:
$ rvm pkg install openssl
Fetching openssl-0.9.8t.tar.gz to /Users/mseeger/.rvm/archives
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3690k 100 3690k 0 0 394k 0 0:00:09 0:00:09 --:--:-- 456k
Extracting openssl-0.9.8t.tar.gz to /Users/mseeger/.rvm/src
Configuring openssl in /Users/mseeger/.rvm/src/openssl-0.9.8t.
Compiling openssl in /Users/mseeger/.rvm/src/openssl-0.9.8t.
Installing openssl to /Users/mseeger/.rvm/usr
$
After that I just reinstalled Ruby and pointed it at the openssl version just to make extra sure:
rvm reinstall 1.9.3-p194 --with-openssl-dir=~/.rvm/usr
After that, the snipped ends up with a 404 as expected.
Lunch and Learn: Cucumber and Capybara
These slides were part of one of the weekly Lunch and Learns at Acquia. A small comparison of old testing methodology (Test-Unit and Selenium) to something we tried on Drupal Commons.
The PDF version of the talk is available for download over here.
Socks and Proxychains as a VPN Alternative
I’ve recently been dabbling with setting up a little homeserver. It runs XBMC, afpd (for TimeMachine) and a good amount of other little scripts and apps that mike my life more automated.
One of the things I would like to have is the ability to access US only services like Hulu from within XBMC.
From the XBMC side, that isn’t all that hard of a task. There are plugins for hulu (video) and the online portfolio of various cable stations (video) available from bluecop’s repository. They certainly aren’t giving the user an experience that is up to par with something like the interface of an Apple TV, but it usually works without too much of a hassle.
One of the problems when setting up this combination is the geo-locked nature of hulu and the other providers. When visiting the Hulu website from my usual German IP address, I am greeted with the usual “NO VIDEO FOR YOU!” message:
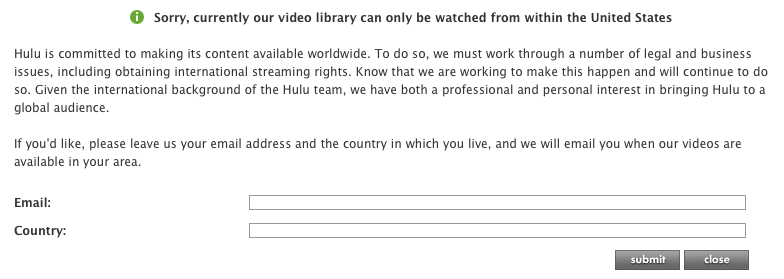
To get arround this, I’ve used VPNs or specialized services in the past. While both of them work pretty decently, I’d rather not force ALL of my traffic over the VPN or pay for a service that I can’t use for much more than Hulu.
One solution would be to go down the VPN route and configure network access based on the user or group using iptables’s owner-match extension, but I honestly don’t like working with iptables and the extension isn’t necessarily available on all systems.
Thanks to @makefoo, I looked a bit more into available “socksification” tools. These tools basically hook TCP/IP kernel methods and redirect them over a SOCKS proxy on a per application level using LD_PRELOAD as far as I understood. This means that you can use them on a per-application level and the only thing you need to point them at is a SOCKS proxy. A SOCKS proxy like the one that SSH is able to provide with the -D flag. So the only real setup I have to do is establishing an SSH connection before I launch the app using something like:
ssh -ND 8765 -i /path/to/certificate [email protected]
Given that you set up a ‘user’ account on your server (.bin/false or /bin/nologin are your friends) and have public key authentication enabled, this will open a local socks proxy on port 8765 and is able to dynamically forward all requests ports through that connection. There are several tools that can do the actual redirection of the network requests. I personally have had good luck with ProxyChains. Other alternatives are TSocks or Dante.
Another big advantage is that this doesn’t need anything running on the remote server besides SSH. I suggest looking at current LowEndBox offers for a cheap VPS. I currently use the “Atlanta OpenVZ VPS - OVZ128” from Quickpacket which comes down to 15 USD a year. I had to ask them for another IP once because the first one wasn’t for some reason detected as being from the US, but besides that it worked great.
If you’re looking for solutions to proxy your Bittorrent traffic, I suggest using Deluge Torrent which supports SOCKS without the need for forced socksification. And at least for Germany, Oderland is a nice swedish VPS provider that has a VPS starting at 2-3 Euros/month.
Thanks to this, I can now do all of my backups straight over my regular connetion and specific programs will use the SSH encryted connection. With my AMD E-450 CPU, I can push 100 mbit/s transfer speed to the internet without a problem.